I jumped down a rabbit hole and made a bunch of posts about what duplicate content is, how it can hurt your site, and how to resolve specific cases (which arise from WordPress settings). I didn’t really mean to go so deep on the topic, though.
To be honest, I haven’t actually encountered many sites that are facing issues with this problem, aside from helping a couple clients set up canonical links for their server migration or site redesign.
What got me going so deep on duplicate content was a question we got from a client.
They were very concerned after getting an error message Google Search Console. When Google gives you error messages, it can be very scary.
- Is your SEO status in bad health?
- Is something broken on your site?
- Is Google Search Console not connected properly?
Our client wasn’t sure what’s going on, so they asked us to look into it.
So let me tell you about the error, how it’s related to duplicate content, and why it indicated that everything was working fine.
The Google Search Console “coverage error”
Google sends bots all over the web to find pages, read the text, and remember the address. This is called “indexing” pages.
When you hear “coverage,” imagine looking at a map and trying to “cover” the area by walking to the different locations on the map. Google tries to cover your site as fully as possible, checking any page it can find.
A “coverage error” is when Google can’t index a page for some reason.
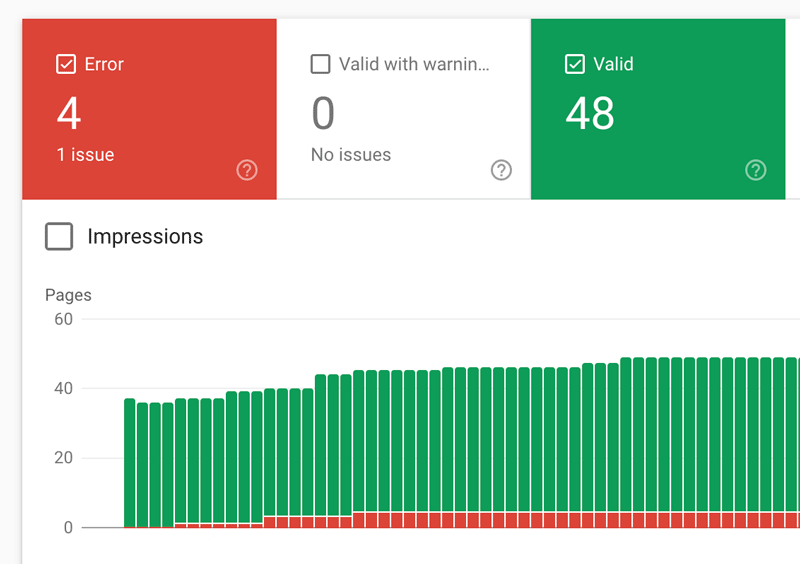
Here is a sample screenshot of the Coverage overview:
- There are 48 successfully indexed pages (the green bars).
- The red bars represent errors — there are 4 pages that Google could see, but could not index
Blog archives
I looked into the pages that are causing errors.
They were all related to the site’s blog archive pages — pages that list up blog posts, often sampling text from the posts.
So why the errors?
The answer to that lies in a combination of two settings that WordPress sets automatically.
- The WordPress XML sitemap — a special page with links to all of the pages you want search engines to scan
- “noindex” setting on blog archive pages — to prevent duplicate content
Here’s the process:
- Google looks at the sitemap and follows all of the links.
- The sitemap includes the blog archive pages — so Google goes and checks there, too.
- When Google gets to the archive pages, they tell Google, “don’t index me.”
Google is confused, and gives an error.
The site told Google to check the archive pages. When it got there, it was told to forget the page. Google gives an error because it seems like something is set wrong.
But, as I explained in another post, the archive pages should be set to noindex. So this error message actually indicates that things are working just fine!
Taking it one step further
In this case, the “errors” being reported are actually indicating that the desired result is, in fact, working. The settings are effectively preventing duplicate content by telling Google not to index the pages.
But, that doesn’t mean this error is something you should necessarily dismiss.
On a larger site, much of your Google crawl budget will be wasted instructing Google to inspect hundreds or thousands of pages it will never index.
Prevent the error to maximize crawl budget
Removing certain pages from the XML sitemap will largely prevent this error. Using a plugin, like All in One SEO will give you very fine control over the sitemap. This can also be done with custom code in your theme or a custom plugin.
